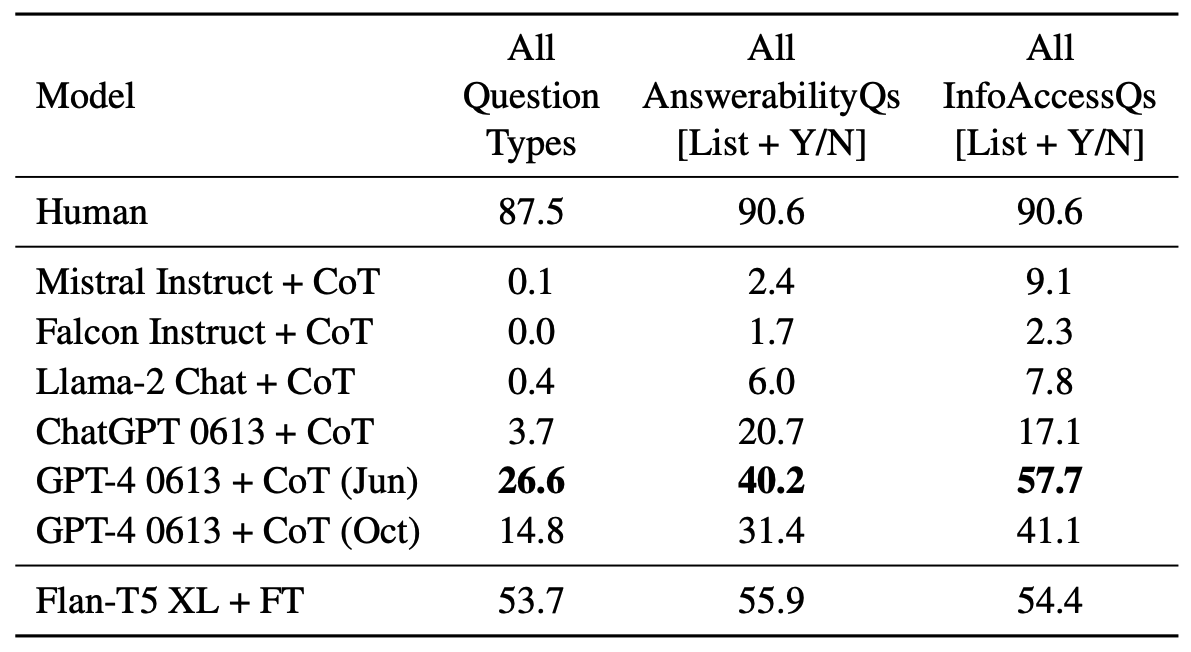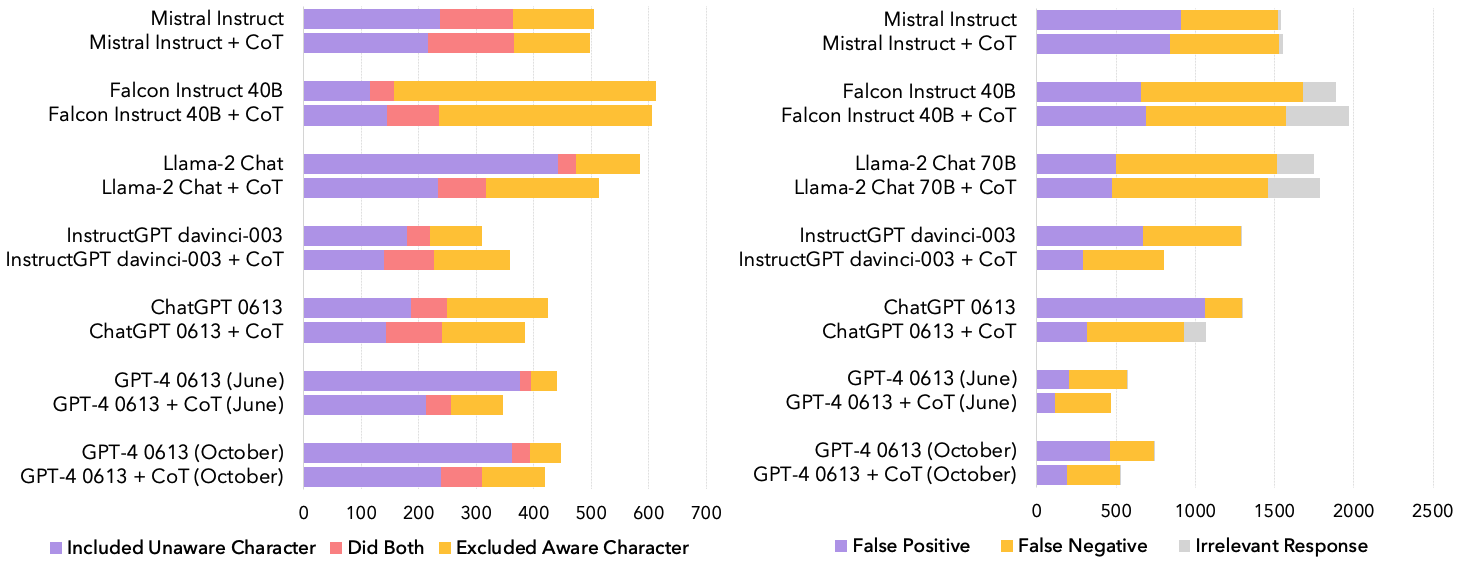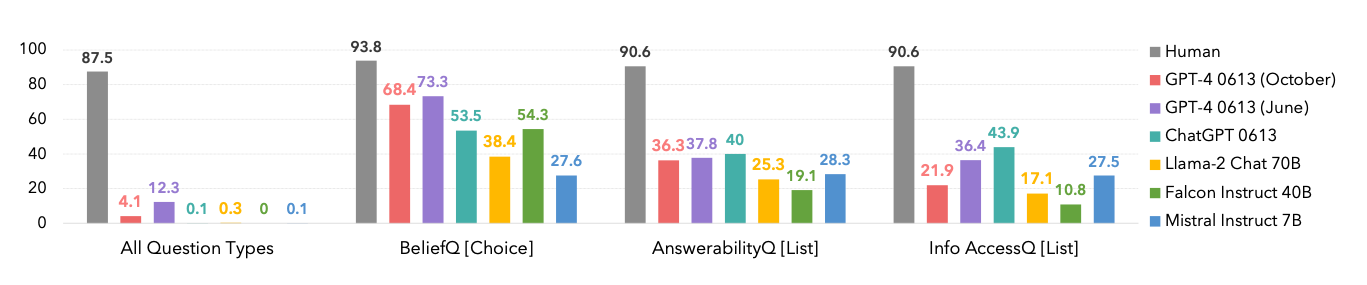
LLMs are tricked
by their own use of shortcuts
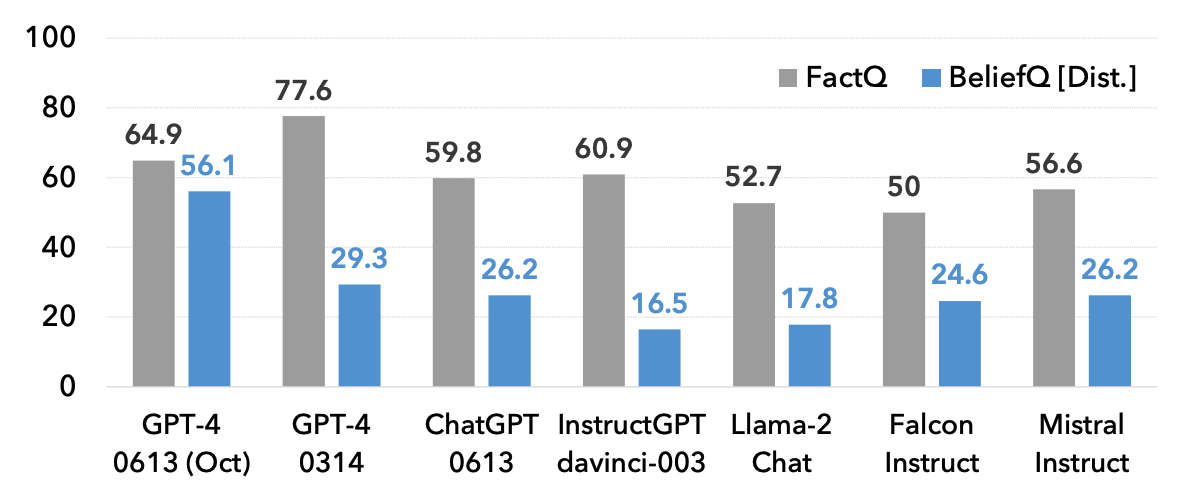
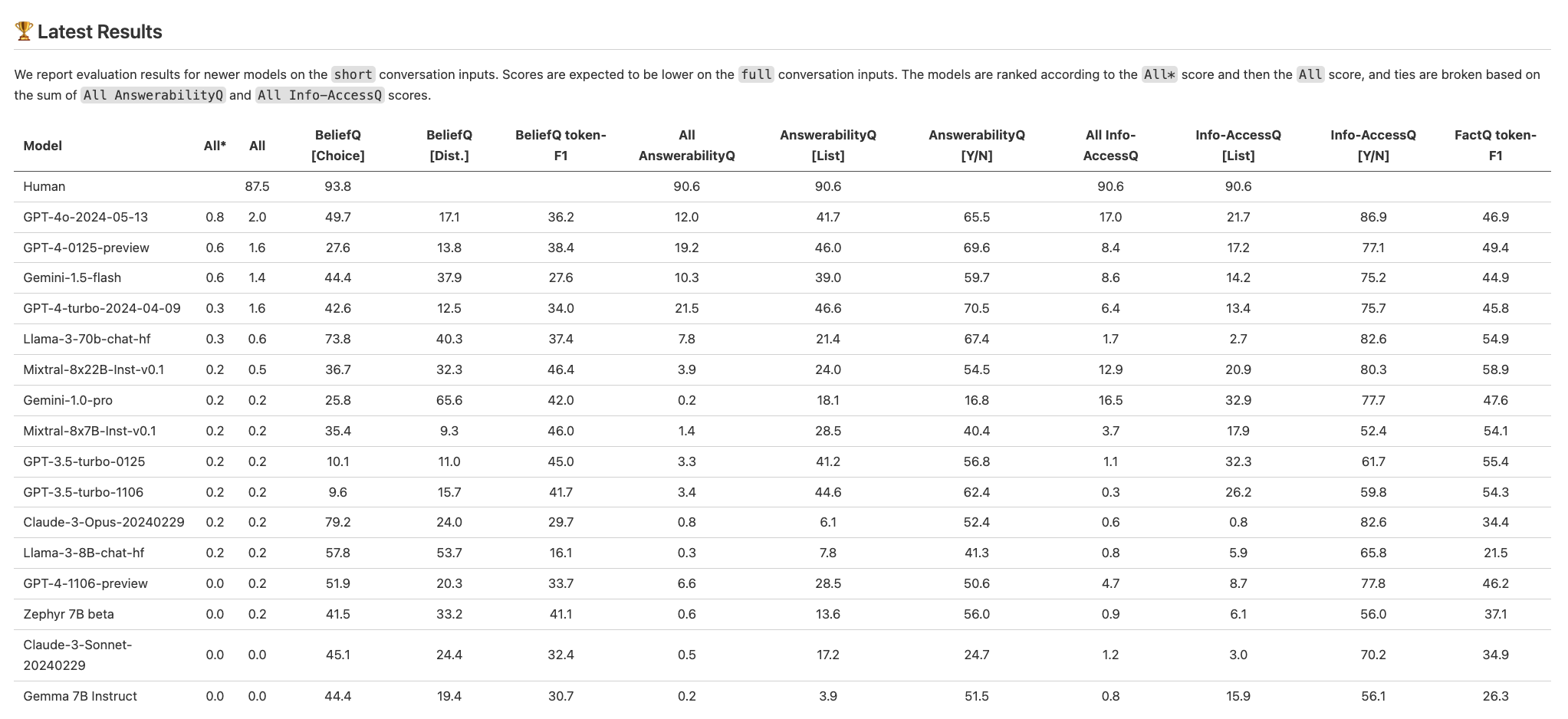
The token F1 scores for FactQ shows the model's basic comprehension capability for interactions. Scoring high in FactQ indicates the model is good at identifying the most relevant information piece to answering the question. Meanwhile, we deliberately design the incorrect answers in BeliefQ[Dist.] to have greater word overlap with the context than correct answers. Also, BeliefQ[Dist.] and FactQ share significant word overlap. Thus, if the model mindlessly copies the most relevant information piece to answering the belief question as well, it will be scoring low accuracy.