KL-divergence
- 초보를 위한 정보이론 안내서 - Entropy란 무엇일까 SERIES 1/3
- 초보를 위한 정보이론 안내서 - Cross Entropy 파헤쳐보기SERIES 2/3
- 초보를 위한 정보이론 안내서 - KL divergence ✓ SERIES 3/3
우리가 지난 시간에 살펴봤던 cross entropy, $H(p,q)$ 에 이어서 이번 글에서는 KL-divergence에 대해 살펴보겠습니다. 사실 단어자체는 cross-entropy만큼 많이 들으셨을 수도 있고 안 들으셨을 수도 있습니다.
Kullback-Leibler divergence
풀네임은 쿨백-라이블러 divergence(발산)입니다. 줄여서 KL-divergence라고 부르곤 합니다. 위키피디아에 나와있는 정의를 살펴보면 이렇게 나옵니다.
쿨백-라이블러 발산(Kullback–Leibler divergence, KLD)은 두 확률분포 간의 차이를 계산한다
두 확률분포의 차이를 계산한다고 나와있는데, 두 분포의 무엇의 차이를 계산하는 것일까요? 바로 엔트로피입니다. 두 분포가 관여하는 개념이었던 cross-entropy를 떠올려봅시다.
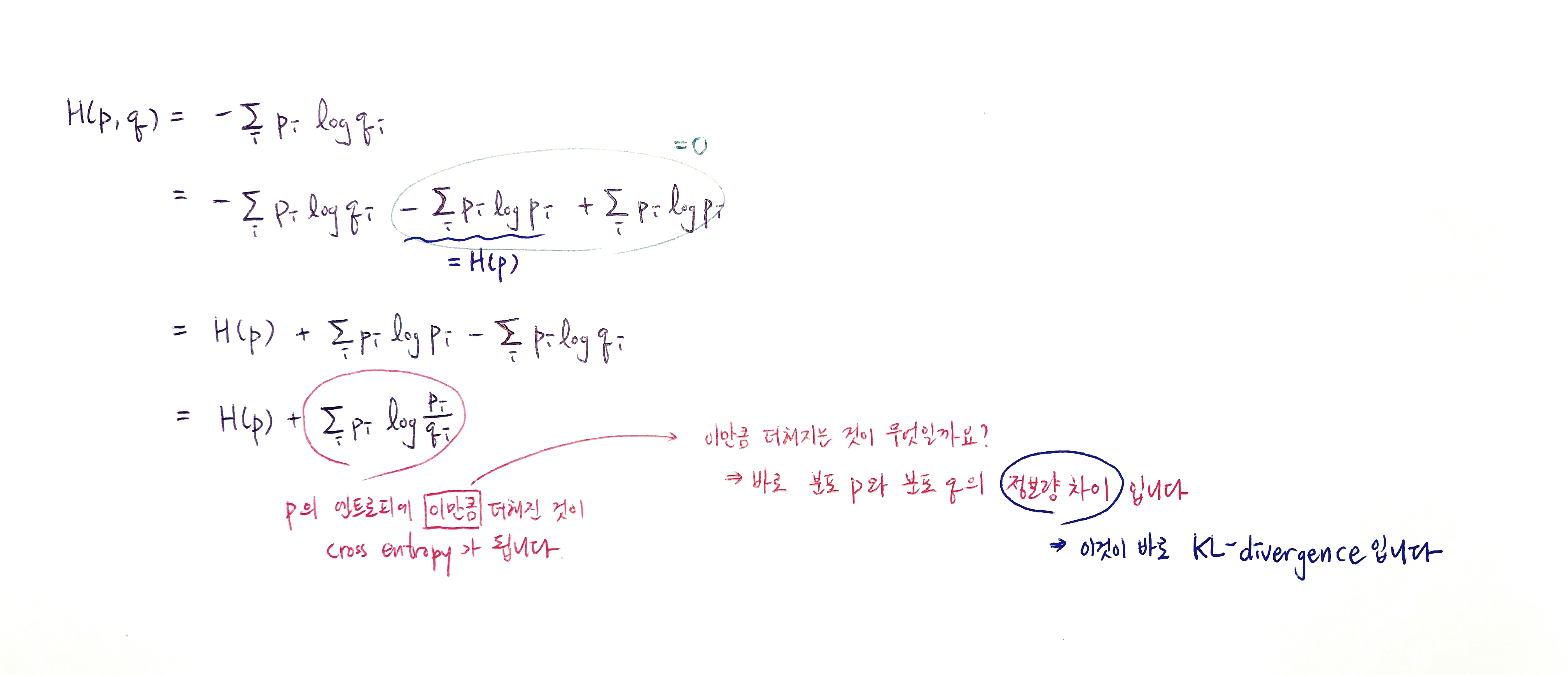
Cross entropy, $H(p,q)$를 전개해보면 그 안에 이미 확률분포 $p$의 엔트로피가 들어있습니다. 그 $H(p)$에 무언가 더해진 것이 cross entropy입니다. 이때 이 무언가의 정체가 바로 KL-divergence 입니다.
KL-divergence의 정확한 식은 이렇습니다. 대개 $D_{KL}(p | q)$ 또는 $KL( p| q)$로 표현합니다.
우리가 대개 cross entropy를 minimize 하는 것은, 어차피 $H(p)$는 고정된 상수값이기 때문에 결과적으로는 KL-divergence를 minimize 하는 것과 같습니다.
KL-divergence의 특성
KL-divergence의 몇 가지 특징들이 있는데, 대표적인 것이 2가지입니다.
- $KL( p| q) \ge 0$
- $KL( p| q) \neq KL(q | p)$
- "KL-divergence는 거리 개념이 아니다"라는 말로 매우 자주 등장합니다
0 이상이다
우선 직관적으로 생각해보면 당연히 0이상일 수밖에 없습니다. 왜냐하면 KL-divergence는 Cross-entropy에서 entropy를 뺀 값이기 때문입니다. Cross entropy는 아무리 작아도 entropy만큼은 가질 수밖에 없는 값이기 때문입니다.
Jensen's Inequality

이 부등식을 사용하려면 우선 convex function, 소위 말하는 아래로 볼록한 함수를 엄밀하게 정의해보겠습니다. 위 그림을 위키피디아에서 찾아봤습니다.
이를 확률론의 맥락에서는 $X$가 random variable이고, $f(\cdot)$가 convex function일 때, 이렇게 표현합니다.
이제 준비운동을 다 마쳤으니 KL-divergence에 관련해서 증명을 해보겠습니다. 우리의 KL-divergence 식에 있는 $-log$ 를 $f(x)$로 두고 가운데의 weighted sum 또는 expectation으로 볼 수 있습니다.
따라서 KL-divergence은 non-negative의 특성을 가집니다.
거리 개념이 아니다
KL-divergence를 검색해보면 알겠지만 가장 귀에 딱지가 앉도록 들리는 말이 바로 "KL-divergence는 거리 개념이 아니다!"입니다. 그러면서 대개 뒤따라오는 설명은 "대칭성을 만족하지 않기 때문이다"라고 합니다. 살펴봅시다.
만약에 두 확률분포 사이의 거리라면 $p$에서 $q$ 사이의 거리나 $q$에서 $p$ 사이의 거리나 같아야 합니다. 하지만 KL-divergence는 그렇지 않습니다. 이런 특성 때문에 우리는 KL-divergence를 distance가 아닌 divergence라고 부르는 것입니다.
Jensen-Shannon divergence
방법은 매우 간단합니다. KL-divergence를 2가지를 구하고는 평균을 내는 방식입니다. 이렇게 간편하게 쓸 수 있지만 Jensen-Shannon divergence는 KL-divergence만큼 널리 사용되지는 않습니다. 대칭성을 만족시키지만 대신 해석이 직관적이지 못하기 때문입니다.
KL-divergence와 log likelihood
우리가 전체를 알 수 없는 분포 $p(x)$ 에서 추출되는 데이터를 우리가 모델링하고 싶다고 가정해보겠습니다. 우리는 이 분포에 대해 어떤 학습 가능한 파라미터 $θ$를 가진 분포 $q(x|θ)$ 로 근사(approximate)하고 싶습니다. 우리가 최소화하고 싶은 KL-divergence를 empirical estimate하면 이렇게 표현할 수 있습니다.
$\ln p(x_n)$ 는 $θ$에 대해 독립이고, $-\ln q(x_n \lvert θ)$ 는 training set으로 얻은 $ q(X \lvert θ)$ 분포 하에서 $θ$ 에 대한 negative log likelihood 입니다. 그러므로 KL-divergence를 minimize한다는 것은 사실상 negative log likelihood를 minimize한다는 것과 같으며, 이는 log likelihood를 maximize한다는 뜻입니다.
정리
Cross entropy는 negative log likelihood와 같습니다. 그래서 cross entropy를 minimize하는 것이 log likelihood를 maximize하는 것과 같습니다. 그리고 확률분포 $p,q$에 관한 엔트로피 $H(p)$가 고정된 값일 때 cross entropy를 minimize하는 것은 KL-divergence를 minimize하는 것과 같습니다. 따라서 우리가 supervised learning에서 하는 많은 것들의 본질은 결국 두 분포 간의 KL-divergence를 최소화하는 과정입니다.
- 초보를 위한 정보이론 안내서 - Entropy란 무엇일까 SERIES 1/3
- 초보를 위한 정보이론 안내서 - Cross Entropy 파헤쳐보기 SERIES 2/3
- 초보를 위한 정보이론 안내서 - KL divergence 쉽게 보기 ✓ SERIES 3/3